







In this new article from the Four essential elements of a winning AI Startup series, Ha Pham, Chief Architect at Apixio, explores a key component of a scalable machine learning (ML) pipeline: the lifecycle of a prediction model from creation to release.
In the broadest sense, prediction models are classifier systems that can be used to make predictions given input data. At Apixio, we extensively use prediction models in making assertions about patients’ conditions across many product offerings. Predictions are ranging from health conditions and treatments to doctor recommendations, for example: Joe is a 58-year-old smoker consider screening for COPD. Let’s explore how we manage a large portfolio of prediction models for multiple product lines and customers.
The most important ML pipeline decision to make early on is to treat prediction models as a software library with a well-defined software interface. This allows the Science and Data Platform teams to independently build different execution systems that serve each team’s specific needs, but still work with the same prediction model.
“You can only support multiple AI products if you can manage multiple ML models in production. An AI model is a library too. Decide early on to treat prediction models as a software library with a well-defined software interface.”
On the one hand, during early model development, our Science team need easy access to their data, flexibility in choice of programming languages, analytics, visualizations, and performance evaluation tooling. Speed of execution, server memory footprint, and detail processing tracking aren’t primary concerns for Science’s execution system.
On the other hand, our Data Platform team’s execution (production) system needs to scale to millions of predictions and have water-tight error detection and self correction. Finely-tuned server configuration, speed of execution, and detailed processing tracking are important characteristics that adhered to religiously.
Model Stages
With this architecture decision in mind, the process of managing prediction models breaks down into three distinct stages:
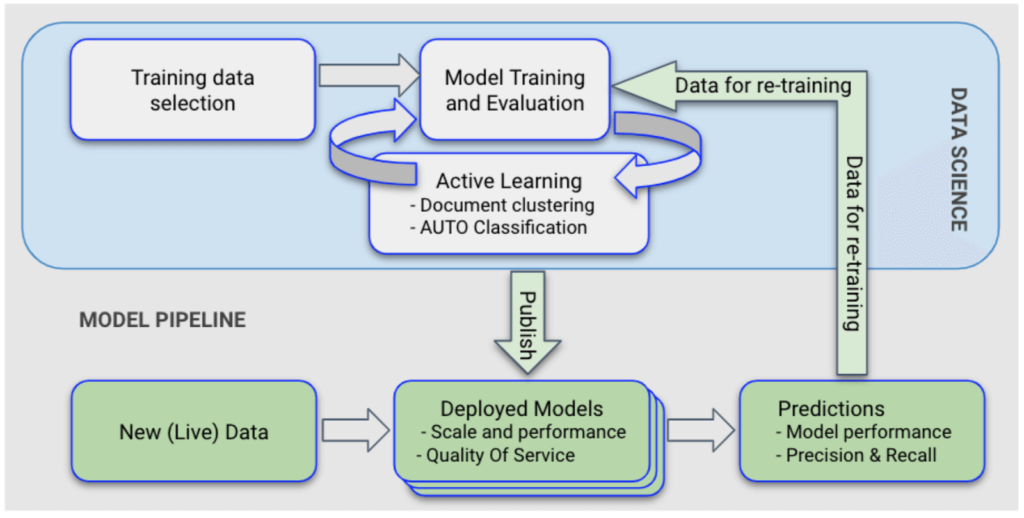
- Stage 1 – Model Development: The Science team formulates, develops, trains, and tests models in their own execution system using a broad range of data science techniques. Once a model is tuned to produce a satisfactory level of predictive performance, it moves on to Stage 2.
- Stage 2 – Model Staging: In this stage, the model is tested to confirm that it retains its predictive performance in Data Platform’s execution system. In addition, an automatic process to test the model congruence (or correctness) is performed. This test guarantees that the production system produces the same predictions as the science system for a sample of data.
- Stage 3 – Model Release: In this stage, the model is used in one or more client projects. Overall model performance, including predictive performance and technical characteristics, occurs as projects unfold, allowing for ongoing monitoring.
Model States
To support this process, in the canonical data constructs, the prediction model is a first-class data type, with its state being the key attribute in the supporting model lifecycle.
- NEW: A model is first created in the NEW state. At this point, the model goes through multiple rounds of training against labeled data and testing against a test data set in the Science system.
- ACCEPTED: Once the model achieves desirable predictive performance in Science’s execution system (i.e. good mix of recall and precision), it moves to the (Science) Accepted state and is ready for model staging.
- DRAFT: The model is moved to DRAFT state, where it’s available for use in Data Platform’s execution system. In this state, the model’s predictive power is verified to ensure it generates identical results to the results from Science’s execution system.
- RELEASED: For a model to be usable in production for client projects, it must be in the RELEASED state. A model can only be RELEASED if it passes a rigorous testing regime to confirm that it maintains predictive power as it moves from running within Science’s execution system to Data Platform’s execution system. As part of this transition, a data scientist must publishes a set of test data and a set of expected test results (aka answer key). Model transition from the ACCEPTED state to the RELEASED state is only allowed if the automated model-verification (Jenkins job) runs the model in Data Platform’s execution system using provided test data and confirms that expected test results are repeatedly reproducible with a 100% match. Through this process, the model’s technical characteristics (configuration verification, memory, CPU, and IO profiling) are also tested again to ensure optimal performance.
Model Catalog Service (MCS)
All models are managed by a microservice called Model Catalog Service (MCS). In addition to the model state, MCS provides a set of tagging mechanisms that allow arbitrary multi-dimensional categorization of models. Models are tagged by product line, medical coding system, and other characteristics. This allows the process of model discovery, selection, and auditing for client projects to be completely trackable. For a client project, a typical flow of model selection would be:
- From project’s attributes such as product line, a MCS query is formed to get the best model that’s compatible with the project criteria.
- A power-user override mechanism is allowed to give operational flexibility. For example, a user may select a specific model combination for one set of patient documents.
- Each action related to model selection is fully logged and available for audit if necessary.
In Summary
Treating prediction models as first-class constructs, with a set of clear entry and exit criteria for models to move from one state to another, allows us to keep track of multiple models throughout their life cycle and monitor how they are deployed in Apixio’s client projects.